Naive Search Algorithm
In computer science, the Naive Search Algorithm (also known as brute-force search) is a basic string matching technique that checks every possible position in the text for the occurrence of a given pattern. Although simple to implement, it is inefficient for large texts and patterns as it performs comparisons one by one without any optimization.
Video Explanation
Overview
The Naive Search Algorithm (also known as brute-force search) is a basic string matching technique that checks every possible position in the text for the occurrence of a given pattern. Although simple to implement, it is inefficient for large texts and patterns as it performs comparisons one by one without any optimization.
Time Complexity:
- Worst Case: O(n * m)
Where: nis the length of the text.mis the length of the pattern.
How It Works
- The algorithm starts at the first character of the text.
- It compares the pattern to a substring of the text of the same length.
- If there’s a mismatch, it moves one position to the right and repeats the comparison.
- If a match is found, it records the position.
- This process continues until the entire text has been checked.
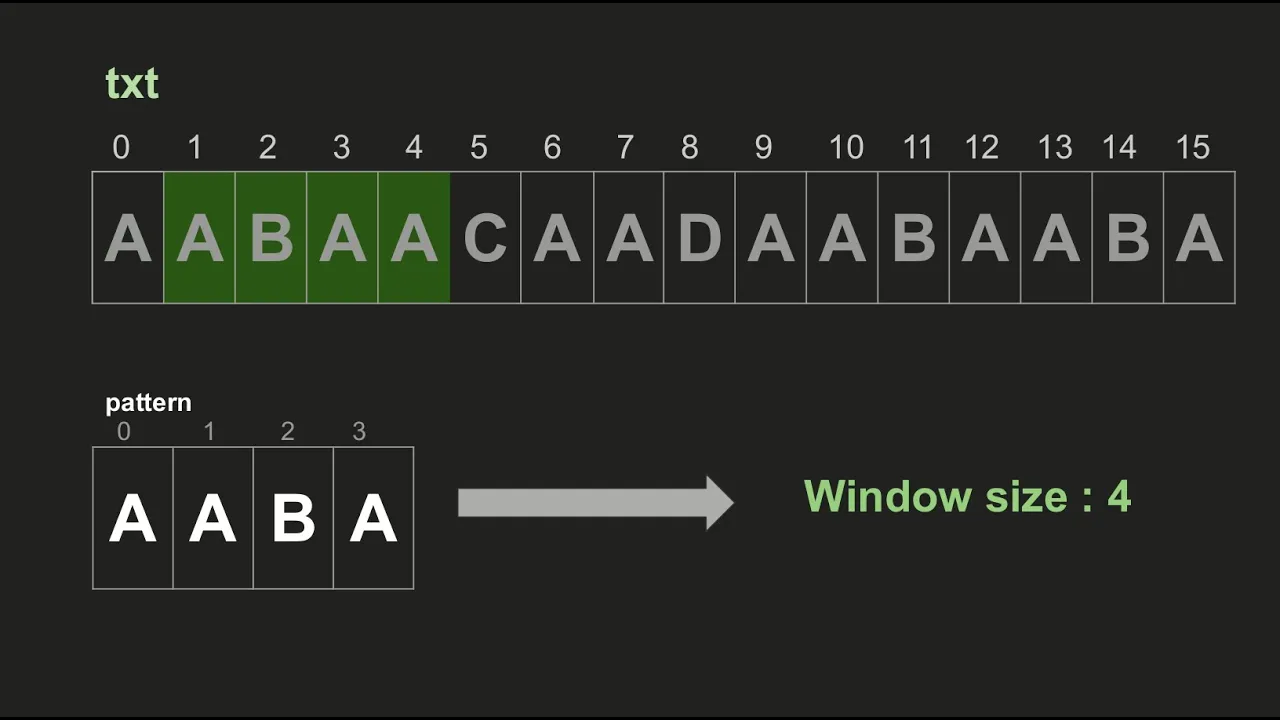
Example
For the text text = "abcabcabc" and pattern pattern = "abc", the naive search will compare:
- Compare
"abc"with the first three characters: Match at index 0. - Move to the next position and compare
"bca", then"cab": Mismatch. - Compare
"abc"with the next"abc"at index 3: Match.
Thus, matches are found at indices 0 and 3.
Code Implementation
Python
def naive_search(pattern, text):
"""Naive search algorithm for pattern matching.
Args:
pattern: The pattern string to search for.
text: The text string where the pattern is to be searched.
Returns:
A list of starting indices where the pattern is found in the text.
"""
m = len(pattern)
n = len(text)
result = []
# Traverse the text and compare each substring of length m with the pattern
for i in range(n - m + 1):
if text[i:i + m] == pattern:
result.append(i)
return result
# Example usage
text = "abcabcabc"
pattern = "abc"
matches = naive_search(pattern, text)
print("Pattern found at indices:", matches)
C++
#include <iostream>
#include <vector>
#include <string>
using namespace std;
vector<int> naive_search(string pattern, string text) {
int m = pattern.length();
int n = text.length();
vector<int> result;
// Traverse the text and compare each substring of length m with the pattern
for (int i = 0; i <= n - m; i++) {
bool match = true;
for (int j = 0; j < m; j++) {
if (text[i + j] != pattern[j]) {
match = false;
break;
}
}
if (match) {
result.push_back(i);
}
}
return result;
}
int main() {
string text = "abcabcabc";
string pattern = "abc";
vector<int> matches = naive_search(pattern, text);
cout << "Pattern found at indices: ";
for (int index : matches)
cout << index << " ";
cout << endl;
return 0;
}
Limitations
- Efficiency: The algorithm performs O(n * m) comparisons in the worst case, which is inefficient for large texts and patterns.
- No Optimization: Unlike more advanced algorithms like Rabin-Karp or Knuth-Morris-Pratt, the naive search algorithm does not use any hashing or preprocessing to improve search times.
Applications
- Educational Use: Due to its simplicity, the naive search is often used to introduce pattern matching algorithms.
- Small-scale Search Problems: Suitable for small text searches or when efficiency is not a primary concern.
Complexity Analysis
-
Time Complexity: The naive search algorithm has a time complexity of in the worst case, where n is the length of the text and m is the length of the pattern.
-
Space Complexity: The space complexity of the algorithm is as it does not require any additional space apart from the input strings.
The naive search algorithm is a simple and intuitive approach to pattern matching but is not suitable for large-scale applications due to its inefficiency. More advanced algorithms like Rabin-Karp, Knuth-Morris-Pratt, or Boyer-Moore are preferred for real-world scenarios.
Conclusion
The Naive Search Algorithm is a basic string matching technique that checks every possible position in the text for the occurrence of a given pattern. Although simple to implement, it is inefficient for large texts and patterns as it performs comparisons one by one without any optimization.
Completed working through this block? Sync progress to workspace.