Finite State Automaton Algorithm
Definition:
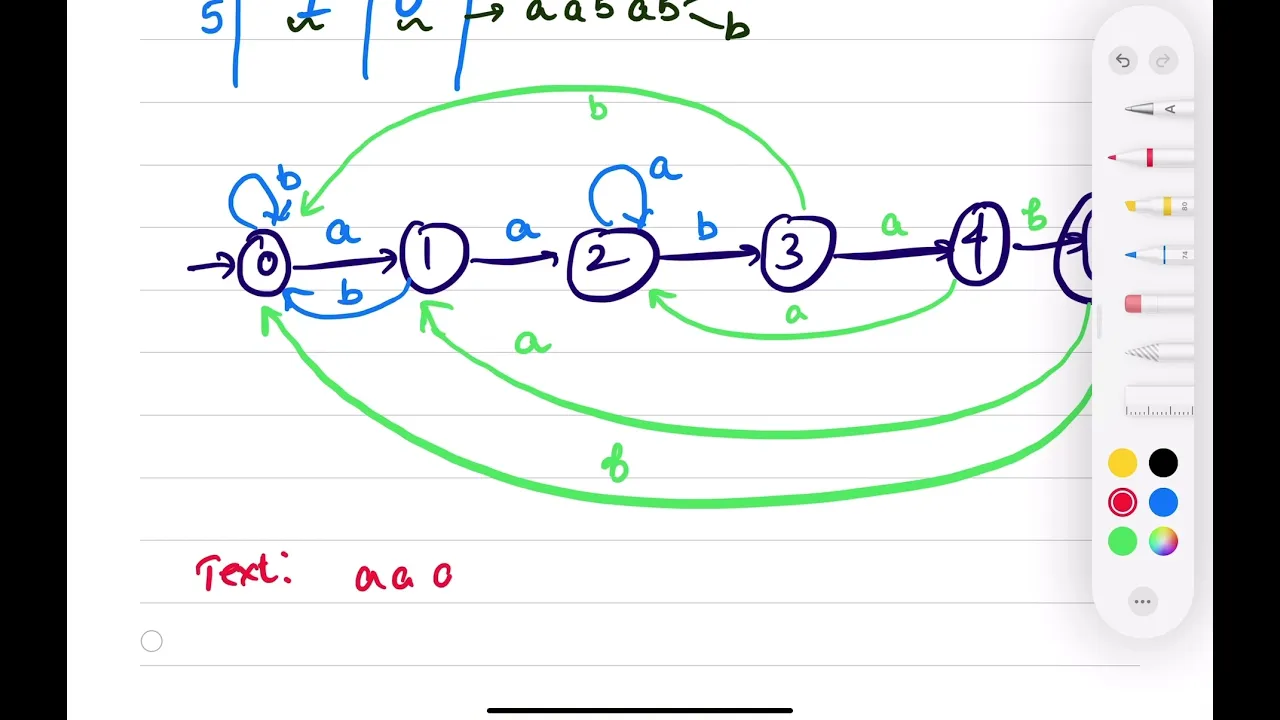
The Finite State Automaton (FSA) algorithm is a string matching technique that constructs a mathematical model of states to perform pattern searching. It builds a state machine from the pattern, where each state represents a prefix of the pattern matched so far. The algorithm then processes the text character by character, transitioning between states to identify matches.
Video Explanation
Characteristics:
-
State-Based Matching:
- The FSA algorithm constructs a deterministic finite automaton (DFA) where states represent the longest prefix of the pattern matched at any point.
- Each state transition is determined by the next character in the input text.
-
Preprocessing Phase:
- Creates a transition table that determines state transitions for each possible character.
- Pre-computation allows for efficient text processing.
-
Exact Matching:
- Designed for exact pattern matching, finding all occurrences of the pattern in the text.
- No approximate matching or wildcards are supported in the basic version.
-
Memory Efficient Processing:
- Once the automaton is constructed, text processing requires minimal additional memory.
- Each character is processed exactly once without backtracking.
Time Complexity:
-
Preprocessing:
- Where m is the pattern length and |Σ| is the size of the alphabet.
- Building the transition table requires computing transitions for each state and character.
-
Pattern Matching:
- Where n is the text length.
- Linear time processing of the text, examining each character exactly once.
Space Complexity:
- Space Complexity:
- Storage required for the transition table, where m is the pattern length and |Σ| is the alphabet size.
- Each state needs transitions defined for every possible character.
C++ Implementation:
#include <iostream>
#include <vector>
#include <string>
using namespace std;
#define CHAR_SIZE 256 // Extended ASCII
class FiniteAutomaton {
private:
vector<vector<int>> transitionTable;
int patternLength;
// Compute prefix function for pattern
int getNextState(string& pattern, int state, char x) {
if (state < patternLength && x == pattern[state])
return state + 1;
for (int ns = state; ns > 0; ns--) {
if (pattern[ns-1] == x) {
int i;
for (i = 0; i < ns-1; i++)
if (pattern[i] != pattern[state-ns+1+i])
break;
if (i == ns-1)
return ns;
}
}
return 0;
}
public:
// Constructor to build the automaton
FiniteAutomaton(string& pattern) {
patternLength = pattern.length();
transitionTable.resize(patternLength + 1, vector<int>(CHAR_SIZE));
// Build transition table
for (int state = 0; state <= patternLength; state++) {
for (int x = 0; x < CHAR_SIZE; x++) {
transitionTable[state][x] = getNextState(pattern, state, x);
}
}
}
// Search pattern in text
void search(string& text) {
int state = 0;
int n = text.length();
for (int i = 0; i < n; i++) {
state = transitionTable[state][text[i]];
if (state == patternLength) {
cout << "Pattern found at index: "
<< i - patternLength + 1 << endl;
}
}
}
};
int main() {
string text = "AABAACAADAABAAABAA";
string pattern = "AABA";
FiniteAutomaton fa(pattern);
fa.search(text);
return 0;
}
Key Features:
-
Pattern Preprocessing:
- Constructs a complete state machine before text processing begins
- Computes all possible transitions for each state
- Handles pattern structure analysis efficiently
-
State Transitions:
- Each state represents a partial match of the pattern
- Transitions are deterministic and pre-computed
- No backtracking required during text processing
-
Failure Functions:
- Handles cases where partial matches fail
- Efficiently moves to the next possible matching state
- Optimizes the matching process for repeated patterns
Applications:
- Text editors and word processors
- Network intrusion detection systems
- DNA sequence analysis
- Compiler lexical analysis
- Pattern matching in large datasets
Summary:
The Finite State Automaton algorithm represents a powerful approach to string matching by utilizing state machines. Its preprocessing phase creates a comprehensive transition table that enables efficient text processing. While the initial preprocessing cost can be significant, especially for large alphabets, the linear-time text processing makes it highly efficient for scenarios where the same pattern is searched multiple times in different texts. The algorithm's deterministic nature and lack of backtracking make it particularly suitable for real-time applications and systems where predictable performance is crucial.
Test Your Understanding
Answer these 3 questions to check what you have learned.
What is the main topic of this documentation page?
What should be identified before implementing finite state automaton?
How is understanding of finite state automaton best checked?
Done with this topic? Mark it as complete to track your progress.