Hierarchical Clustering Visualizations
Definition:
Hierarchical Clustering is an unsupervised machine learning technique that creates a hierarchy of clusters, allowing data points to be grouped based on their similarities. This method can be performed in two ways: agglomeratively (bottom-up) and divisively (top-down).
Video Explanation
Characteristics:
-
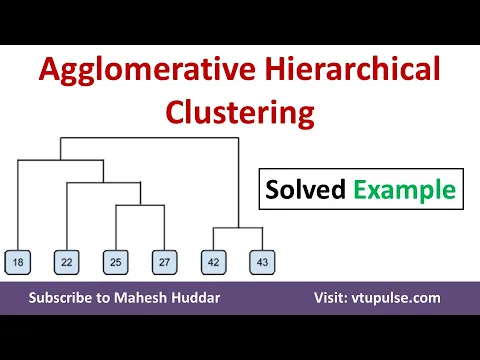
Dendrogram Representation:
Hierarchical clustering can be visualized using a dendrogram, which illustrates the relationships between clusters at various levels of granularity. -
Flexible Number of Clusters:
Unlike K-Means, hierarchical clustering does not require specifying the number of clusters in advance. -
Distance Metrics:
Various distance metrics (e.g., Euclidean, Manhattan) and linkage criteria (e.g., single, complete, average) can be used to determine how clusters are formed.
Components of Hierarchical Clustering:
-
Clusters:
Groups of similar data points that are merged or split during the clustering process. -
Dendrogram:
A tree-like diagram that shows the arrangement of clusters and the distances at which merges or splits occur. -
Linkage Criteria:
Methods used to define the distance between clusters, affecting the shape and size of the resulting clusters.
Steps Involved:
-
Choose a Distance Metric:
Select a method to measure the distance between data points. -
Build the Dendrogram:
Start with each data point as its own cluster and iteratively merge clusters based on the selected distance metric and linkage criteria. -
Cut the Dendrogram:
Determine the number of clusters by cutting the dendrogram at a specified height. -
Assign Clusters:
Based on the cuts, assign data points to their respective clusters.
Key Concepts:
-
Agglomerative Clustering:
A bottom-up approach where each data point starts as a separate cluster and clusters are merged based on distance. -
Divisive Clustering:
A top-down approach that starts with one cluster and recursively splits it into smaller clusters. -
Linkage Methods:
Common methods include single linkage (minimum distance), complete linkage (maximum distance), and average linkage (mean distance).
Advantages of Hierarchical Clustering:
-
Intuitive Visualization:
The dendrogram provides a clear visual representation of the clustering process and relationships. -
No Need for Predefined K:
Users can choose the number of clusters after inspecting the dendrogram. -
Handles Different Cluster Shapes:
Can capture clusters of various shapes and sizes, unlike K-Means.
Limitations of Hierarchical Clustering:
-
Computationally Intensive:
The time complexity can be high, especially for large datasets, making it less suitable for very large datasets. -
Sensitive to Noise:
Outliers can distort the clustering structure and affect results. -
Linkage Dependency:
The choice of linkage method can significantly influence the resulting clusters.
Popular Applications of Hierarchical Clustering:
-
Genomics:
Used to group genes or samples based on expression data to identify biological patterns. -
Market Research:
Helps in segmenting customers based on purchasing behavior for targeted marketing strategies. -
Document Clustering:
Groups similar documents for efficient retrieval and organization. -
Image Segmentation:
Clusters similar pixels to delineate objects within images. -
Social Network Analysis:
Identifies communities or groups within social networks based on interaction patterns.
Example of Hierarchical Clustering in Python:
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import make_blobs
from scipy.cluster.hierarchy import dendrogram, linkage
# Create a sample dataset
X, _ = make_blobs(n_samples=100, centers=3, cluster_std=0.60, random_state=0)
# Perform hierarchical clustering
linked = linkage(X, method='ward')
# Create a dendrogram
plt.figure(figsize=(10, 7))
dendrogram(linked, orientation='top', distance_sort='descending', show_leaf_counts=True)
plt.title('Hierarchical Clustering Dendrogram')
plt.xlabel('Sample Index')
plt.ylabel('Distance')
plt.show()
Time and Space Complexity:
-
Time Complexity:
The time complexity is generally for the basic implementation, but more efficient methods exist. -
Space Complexity:
The space required is for storing distance matrices.
Summary & Applications:
-
Hierarchical Clustering is a versatile technique that provides valuable insights into data structures and relationships, making it essential for exploratory data analysis.
-
Applications:
Effective in various fields such as genomics, marketing, and image processing, helping uncover patterns and facilitate decision-making.
Completed working through this block? Sync progress to workspace.