Hierarchical Clustering Algorithm
Hierarchical Clustering Algorithm
Hierarchical clustering is a method of grouping similar data points into clusters based on their relative distances from each other. Unlike flat clustering techniques such as k-means, hierarchical clustering does not require a pre-specified number of clusters. Instead, it creates a hierarchy of clusters that can be visualized as a dendrogram, showing the hierarchical relationship between clusters.
Video Explanation
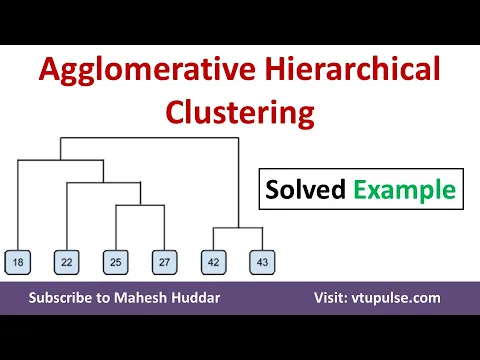
Table of Contents
- Introduction
- How It Works
- Types of Hierarchical Clustering
- Linkage Methods
- Benefits and Use Cases
- Implementation
Introduction
Hierarchical clustering is an unsupervised machine learning algorithm that builds a multi-level hierarchy of clusters. This hierarchical structure allows users to choose their desired number of clusters based on the level of detail they need. Hierarchical clustering is often applied in:
- Biology: for phylogenetic tree construction to show relationships among species.
- Social Sciences and Psychology: to cluster people based on survey data or behavioral patterns.
- Marketing: to segment customers based on their purchasing behavior.
- Text Analysis: to group similar documents or articles together.
Unlike methods like k-means clustering, hierarchical clustering does not require users to specify the number of clusters in advance. Instead, clusters are determined based on distances between data points and merge or split until a single cluster or the desired cluster number is achieved.
How It Works
Hierarchical clustering uses a distance metric to calculate the similarity between points or clusters. In the agglomerative approach (bottom-up):
- Each data point begins as its own cluster.
- Calculate the distance between each pair of clusters using a chosen linkage criterion.
- Merge the two closest clusters.
- Repeat steps 2-3 until only one cluster remains or a specified number of clusters is reached.
In the divisive approach (top-down):
- All data points start in one large cluster.
- This cluster is split into smaller clusters recursively until each data point is its own cluster or a predefined threshold is met.
The results can be visualized with a dendrogram, a tree-like diagram showing the order and level of merges or splits.
Types of Hierarchical Clustering
Agglomerative (Bottom-Up)
In the agglomerative approach, each data point is initially its own cluster, and clusters are iteratively merged based on similarity. This approach is more common due to its intuitive nature and ease of implementation.
Divisive (Top-Down)
The divisive approach begins with a single cluster containing all data points and recursively splits it. Although less commonly used, it can be more effective in some cases, particularly for datasets with natural group separations.
Linkage Methods
The linkage method determines how the distance between clusters is calculated when they are merged or split. Common linkage methods include:
-
Single Linkage: The distance between two clusters is defined as the minimum distance between any two points in the two clusters. This often results in "chain-like" clusters.
-
Complete Linkage: The distance between two clusters is defined as the maximum distance between any two points in the two clusters, leading to compact clusters.
-
Average Linkage: The distance between two clusters is defined as the average distance between all pairs of points in the two clusters.
-
Ward’s Method: This linkage minimizes the total variance within clusters. It is often preferred when clusters are expected to be roughly spherical.
Each linkage method produces different cluster shapes, and the choice of linkage can significantly affect the final clustering outcome.
Benefits and Use Cases
Benefits
- Flexibility: Hierarchical clustering can produce a range of cluster sizes and numbers, allowing for detailed exploration of data structure.
- Visualization: The dendrogram provides a clear, visual representation of how clusters relate at different levels, which is useful for understanding the data's structure.
- No Need to Predefine Cluster Count: Hierarchical clustering does not require the user to specify the number of clusters in advance, which is often a requirement in methods like k-means.
Use Cases
- Biological Data Analysis: Constructing phylogenetic trees or understanding genetic similarity between species.
- Market Segmentation: Grouping customers by purchasing patterns or demographics.
- Document Classification: Organizing large collections of text data into meaningful categories.
- Image Segmentation: Grouping pixels or image features for applications in computer vision.
Implementation
Dependencies
Ensure you have the following libraries installed:
pip install scipy matplotlib
Python Implementation
import numpy as np
from scipy.cluster.hierarchy import dendrogram, linkage, fcluster
from scipy.spatial.distance import pdist
import matplotlib.pyplot as plt
# Sample data (2D points)
data = np.array([
[1, 2],
[2, 3],
[3, 4],
[5, 6],
[8, 8],
[7, 7],
[8, 9]
])
# Step 1: Compute the pairwise distance matrix
distance_matrix = pdist(data)
# Step 2: Perform hierarchical clustering using a specified linkage method
Z = linkage(distance_matrix, method='single') # Options: 'single', 'complete', 'average', 'ward'
# Step 3: Visualize the clustering as a dendrogram
plt.figure(figsize=(10, 7))
dendrogram(Z, labels=[f'Point {i+1}' for i in range(len(data))])
plt.title("Hierarchical Clustering Dendrogram")
plt.xlabel("Data Points")
plt.ylabel("Distance")
plt.show()
# Step 4: Extract clusters by setting a threshold
threshold = 3 # Adjust threshold based on dataset and desired cluster separation
clusters = fcluster(Z, threshold, criterion='distance')
print("Cluster Assignments:", clusters)
# Optional: Scatter plot of clustered data
plt.figure(figsize=(8, 5))
plt.scatter(data[:, 0], data[:, 1], c=clusters, cmap='rainbow', s=100)
plt.title("Hierarchical Clustering - Clustered Data Points")
plt.xlabel("X-axis")
plt.ylabel("Y-axis")
plt.show()
Completed working through this block? Sync progress to workspace.