CatBoost Algorithm
Definition:
CatBoost (Categorical Boosting) is a gradient boosting algorithm designed to handle categorical data directly without the need for extensive preprocessing. It is particularly effective in problems with categorical features, offering high performance and reducing the need for extensive hyperparameter tuning.
Video Explanation
Characteristics:
-
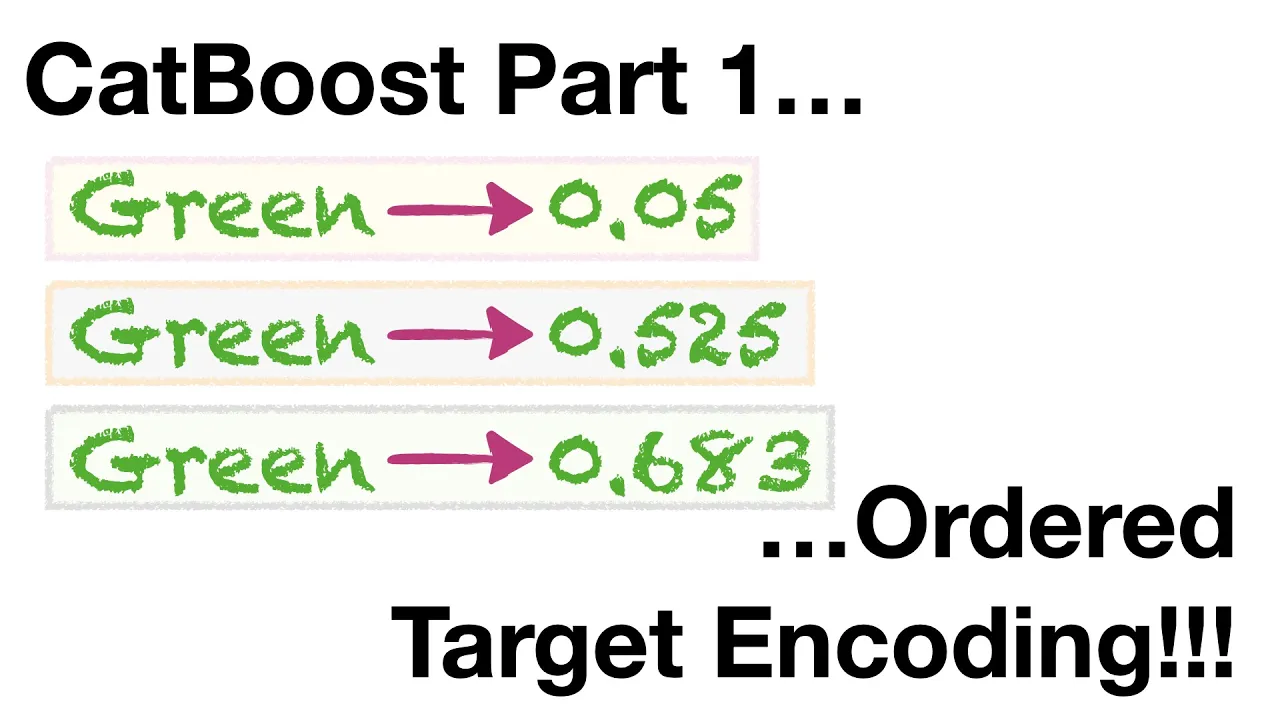
Handles Categorical Features: CatBoost automatically processes categorical features without one-hot encoding, saving time and improving performance in tasks with significant categorical data.
-
Boosting Method: Like other gradient boosting methods, CatBoost builds an ensemble of decision trees sequentially, where each tree is designed to correct the mistakes of the previous one.
-
Efficient and Fast: CatBoost is optimized for speed and performance, with built-in support for parallel computation and advanced optimization techniques that make it faster than many other gradient boosting algorithms.
-
Low Overfitting: CatBoost incorporates regularization techniques that help reduce overfitting, even when the model is trained on small or noisy datasets.
Steps Involved:
-
Initialize the Model: CatBoost starts by initializing a base model (typically a weak classifier) and computes the loss between predicted and actual values.
-
Iterative Boosting: Sequentially add trees, with each tree correcting the errors of the previous model. The objective is to minimize the loss function after each iteration.
-
Handle Categorical Features: Automatically process and encode categorical features without the need for preprocessing like one-hot encoding, significantly reducing the preprocessing time.
-
Predict and Aggregate: The final prediction is aggregated by combining the outputs of all trees, weighted by their contribution.
Problem Statement:
Given a dataset, the goal of CatBoost is to iteratively build a strong predictive model by combining weak decision trees, with particular attention to handling categorical data directly. This makes it a robust choice for datasets with many categorical variables, helping to improve model accuracy and reduce computational time.
Key Concepts:
-
Boosting:
A technique that combines multiple weak learners into a strong model by sequentially correcting their errors. -
Categorical Features:
Variables with a finite set of categories or labels, such as colors or product types, which CatBoost handles natively. -
Learning Rate:
A parameter that controls the contribution of each new tree to the model, balancing the speed of learning and model generalization.
Objective Function:
The objective function minimized by CatBoost is defined as:
Where:
- is the loss function measuring the difference between true values () and predicted values ().
- is the regularization term penalizing the complexity of the model.
Time Complexity:
- Best, Average, and Worst Case:
CatBoost optimizes tree construction with a greedy algorithm, achieving logarithmic time complexity for each tree based on the number of training instancesn.
Space Complexity:
- Space Complexity:
The memory footprint grows with the number of data points, as CatBoost needs to store gradient and Hessian information for each instance during training.
Python Implementation:
Here is a basic implementation of CatBoost in Python using the CatBoost library:
from catboost import CatBoostClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Load dataset
data = load_breast_cancer()
X, y = data.data, data.target
# Split into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create CatBoost model
model = CatBoostClassifier(iterations=100, learning_rate=0.1, depth=6)
# Train model
model.fit(X_train, y_train)
# Make predictions
predictions = model.predict(X_test)
# Calculate accuracy
accuracy = accuracy_score(y_test, predictions)
print(f'Accuracy: {accuracy}')
Summary:
CatBoost is a powerful gradient boosting algorithm, specifically designed to handle categorical features efficiently. Its ability to directly process categorical data, combined with robust performance and low overfitting, makes it a popular choice for various classification and regression tasks.
Completed working through this block? Sync progress to workspace.