Knuth-Morris-Pratt (KMP) Algorithm
The Knuth-Morris-Pratt (KMP) algorithm is an efficient string-matching algorithm that searches for occurrences of a "pattern" string within a "text" string. It improves the search process by avoiding unnecessary comparisons, thus reducing the time complexity.
Video Explanation
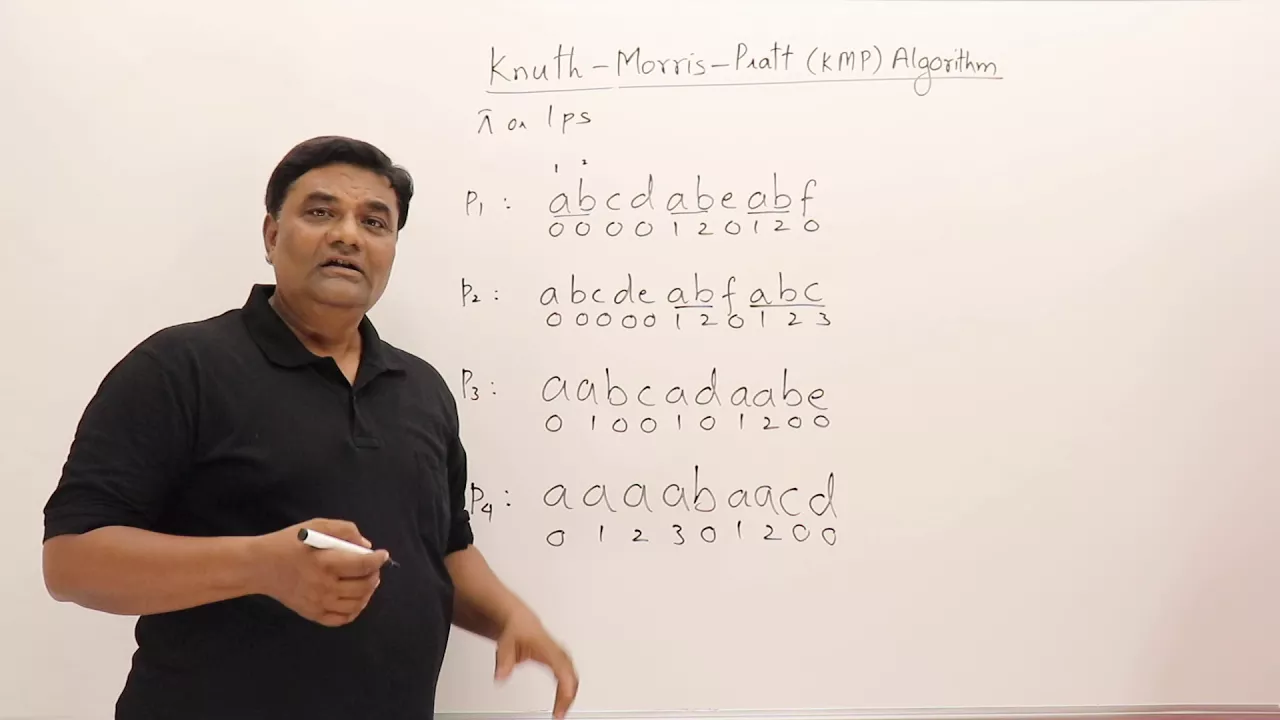
Introduction
In traditional substring search algorithms, such as the naive approach, the time complexity can be as high as O(n * m), where n is the length of the text and m is the length of the pattern. The KMP algorithm optimizes this by preprocessing the pattern to determine the longest prefix which is also a suffix, allowing it to skip unnecessary comparisons.
Characteristics of KMP Algorithm
- Efficiency: The KMP algorithm runs in O(n + m) time, making it much more efficient for longer texts and patterns.
- Preprocessing: It preprocesses the pattern to create a longest prefix suffix (LPS) array, which guides the search process.
- No Backtracking: Unlike naive algorithms, KMP does not backtrack the text pointer, ensuring a linear scan.
How KMP Algorithm Works
-
Preprocessing:
- Create an LPS (Longest Prefix Suffix) array that holds the length of the longest proper prefix which is also a suffix for each prefix of the pattern.
- This array helps determine how many characters to skip when a mismatch occurs.
-
Searching:
- Compare the characters of the text and pattern.
- If there is a match, move to the next character in both the text and pattern.
- If a mismatch occurs after some matches, use the LPS array to skip the necessary characters in the pattern without moving the text pointer backward.
Step-by-Step Execution
Let's illustrate the KMP algorithm with a simple example:
- Text:
ABABDABACDABABCABAB - Pattern:
ABABCABAB
LPS Array Construction
- Initialize an LPS array for the pattern.
- Fill the LPS array by tracking the longest prefix which is also a suffix.
For the pattern ABABCABAB, the LPS array is constructed as follows:
A: 0AB: 0ABA: 1ABAB: 2ABABC: 0ABABCA: 1ABABCAB: 2ABABCABA: 3ABABCABAB: 4
The final LPS array is: [0, 0, 1, 2, 0, 1, 2, 3, 4].
Searching Process
- Start with the text pointer and pattern pointer at the beginning.
- Compare characters. If they match, move both pointers forward.
- On a mismatch, use the LPS array to skip characters in the pattern.
- Start: Text:
ABABDABACDABABCABAB, Pattern:ABABCABAB - Matches:
A,B,A(text[0] to text[2]) - Mismatch at text[3]:
D(next pattern index from LPS is 2) - Shift pattern by 2 positions based on LPS.
Repeat the comparison until the end of the text.
Time Complexity
- The KMP algorithm runs in O(n + m) time, where n is the length of the text and m is the length of the pattern. This efficiency is achieved due to the preprocessing step and the avoidance of backtracking.
Applications
- Text Searching: Efficiently searching for a substring in a large text.
- Data Mining: Useful in pattern matching in databases and search engines.
- Bioinformatics: Searching DNA sequences for patterns.
- Text Editors: Used in find functionalities in text processing applications.
Pseudocode
def KMPSearch(text, pattern):
# Create LPS array
lps = computeLPSArray(pattern)
i = 0 # index for text
j = 0 # index for pattern
while i < len(text):
if pattern[j] == text[i]:
i += 1
j += 1
if j == len(pattern):
print("Pattern found at index " + str(i - j))
j = lps[j - 1]
elif i < len(text) and pattern[j] != text[i]:
if j != 0:
j = lps[j - 1]
else:
i += 1
def computeLPSArray(pattern):
length = 0 # length of previous longest prefix suffix
lps = [0] * len(pattern)
i = 1
while i < len(pattern):
if pattern[i] == pattern[length]:
length += 1
lps[i] = length
i += 1
else:
if length != 0:
length = lps[length - 1]
else:
lps[i] = 0
i += 1
return lps
Advantages of KMP Algorithm
Optimal Time Complexity: The KMP algorithm efficiently handles pattern searching in linear time. No Redundant Comparisons: Avoids unnecessary re-evaluation of characters in the text. Flexible: Can be applied to various string processing applications.
Limitations
Space Complexity: Requires additional space for the LPS array, which may not be suitable for memory-constrained environments. Preprocessing Overhead: The preprocessing step adds a minor overhead, which may not be beneficial for very short patterns or texts.
Conclusion
The Knuth-Morris-Pratt (KMP) algorithm is a powerful string-searching technique that optimizes the process of substring searching. Its linear time complexity and efficient handling of mismatches make it an essential algorithm in computer science and various practical applications. Understanding KMP allows developers to implement efficient pattern matching in string processing tasks.
Done with this topic? Mark it as complete to track your progress.